You're Already Estimating Your Software Projects
- You Are Always Estimating
- Why Does This Matter?
- How Many Candies Does Your Code Have?
- Getting Back on Track
The industry debate over software estimation is one of false alternatives: either you are pro-estimation or you are anti-estimation and that is effectively the end of the story.1
Unfortunately this dichotomy is a complete misdirection, confounds understanding, and ultimately leaves teams and organizations throwing their hands up in the air and missing out on practical ways to significantly reduce risk of failure in their software projects.
The truth is that everyone estimates their software projects—in actual time units!—whether they are fully aware of it, or not; the primary difference is only in whether one reifies (writes down) their estimates or not.
You Are Always Estimating
One of the most repeated, and understandable, points from anti-estimation proponents is that because estimates are inaccurate, we can conclude they’re worthless and simply ignore them. But any decision to initiate a software project (or project iteration) is ultimately rooted in some assumption about time—i.e., an estimate.
Rarely does one start a software project—or individual task for that matter—without some assumption about how long it could take. There is always an assumption about time, even if that assumption is tacit and unspoken.
- When an experienced tech lead takes on a large project, she assumes some time-based scope to the work; it is rarely a good look for one’s career prospects to be working on a technical project for years with no deliverable or outcomes.
- When a manager or tech lead assigns a task to a new engineer on a project, the general assumption is that the task has some time-oriented scope; it would be downright cruel to give a new junior their first task that was expected to take a year or even several months.
- It goes without saying that serious entrepreneurs & startups expect to deliver something specific within the scope of their runway—even if it is a non-production artifact like a prototype to obtain a next round of funding.
Of course, we could keep going with this list. Even the most anti- of the anti-estimation set will find themselves—possibly sotto voce, behind a closed office door—asking, or answering: “How long do you think that’ll take?”
The point is this, though. There is no sensible business context in which time doesn’t matter for some software effort. We are always estimating, even if we are doing it intuitively or unconsciously.
Furthermore, we effectively estimate this way not just at the launch of a project but at each day and each week that we continue in our efforts: that is, we are always assuming that the work ahead of us fits into some reasonable scope of time. If we believed otherwise, we’d stop or switch priorities.
Why Does This Matter?
This is not just a rhetorical point. There is a fundamental misunderstanding in the popular discourse about the value of estimating, and it has dramatic cost to software delivery outcomes.
The question is not whether we should be estimating; we already are all the time. The question is whether we should be writing down our estimates as we make or revise them.
To the credit of the anti-estimation crowd, estimates are almost always inaccurate out of the gate. But here is one of the fallacies in the estimation debate: the idea that estimates must be correct before we consider them of value.
This fallacy that estimates must be initially correct is where the train first goes off the tracks for many people: it is how we, as the software industry, end up with either an outright disdain for estimates, or—worse—a purposeful distortion of estimates by replacing time-based estimates with things like “story points”, “dev units”, T-shirt sizing, and the like: i.e., fantasy units devised to purposefully hide our inaccuracies.
To understand why these reactions are so counterproductive and damaging, we should consider what would happen if we approached other areas of our work in the same manner.
How Many Candies Does Your Code Have?
Imagine if we took the same approach with our software code that we took with estimates.
Just as with estimates, our code is regularly wrong. Either because it has accidental defects or performance issues, because our understanding of our domain has changed, because the market or product requirements have evolved, etc. In all such cases, our code is wrong by any measure and requires modification.2
But unlike with estimation, we can’t avoid writing our code down; our compilers and runtime environments wouldn’t have it. We could, however, try to distort matters—as some do with estimates, when they replace time units with story points and the like—in order to limit exposing ourselves to our own inevitable code mistakes.
Instead of identifying defects, performance issues, and feature gaps in our code and working to prioritize and fix them, we could instead bucket issues together under a new pleasant-sounding name—say, “candies”—and try to make decisions within this new vocabulary.
“We discovered approximately five pieces of candy—two small and three big—in our code today.”
This sounds a lot nicer than reality, but it leaves us with much less ability to make rational and risk-reducing decisions about where we should go next. Most people would agree that defects should be prioritized and fixed each according to estimable qualities: severity, customer impact, time-to-fix, etc. By obfuscating things with an artificial vocabulary, we blindfold ourselves from rational decision-making.
Of course most of us would deem this approach to code absurd, but we don’t balk when a similar approach is applied to writing down our estimates and plans.
“We discovered four more tasks to complete before we can go live with Feature X—all T-shirt sizes Adult Medium…”
Getting Back on Track
The pro-estimates and anti-estimates debate has forced many in the industry into this absurdity.
But the truth is there is no reason to distort reality with fantastical vocabulary (story points, dev units, candies, or what-have-you), nor is there reason to entirely mask reality by pretending that we’re not estimating when we effectively are.
How did we lose our way, and how do we get back?
We lost our way because we did this:
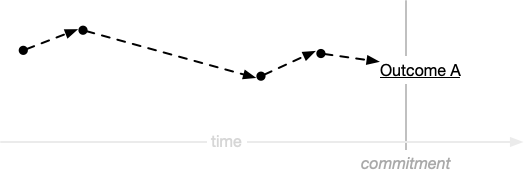
We wrote down our plans (tasks and corresponding estimates) and then immediately “published” our upstream commitments to the initial—certainly inaccurate—version of our plan.
The equivalent if we did this with code would be announcing to customers that we were feature- or product-complete, the minute any relevant code was committed anywhere, before any completeness, quality assurance, performance testing measures were taken. Once again, most of us would consider this absurd.
So, of course, we were doomed to failure. Along the way, our actual steps diverge from our original conception. We inevitably discover new tasks and we lengthen and shorten other tasks and then blow past our commitment:
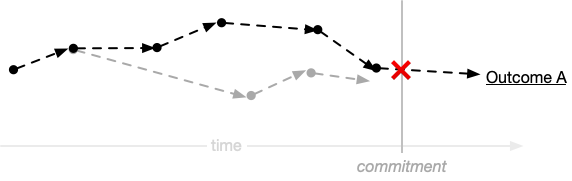
When it comes to our code, we have specific measures and tooling to protect ourselves against defects and performance issues. These measures are understood by industry and tailored uniquely for the particular teams and business contexts that leverage them. Unit testing, continuous delivery processes and tools, peer code review, including checklist-based code reviews, and so on.
These measures have all evolved to allow us to ship product to customers with explicit or implicit quality and SLA guarantees.
Planning and estimation deserve the same industry attention and evolution of tooling and processing that we’ve given to code, without any purposeful obfuscation.
The way back to sanity is to write down our plans (tasks and estimates—in real time units) and embrace, as we do with code, that they’ll be inaccurate. That is, we must not treat plans as static artifacts; we must regularly evaluate our plans and continuously refactor them. (As with code, we can leverage the help of tooling for both evaluation and refactoring.)
If we can apply processes and tooling to ensure sufficient defect rates and performance latencies within our software systems, then we can certainly apply processes and tooling to ultimately determine reliable delivery times. Both are a matter of process, tools and skill set, and we don’t need to obfuscate either.
Code processes are familiar. What processes can we apply to our plans and estimates?
- Peer review. Much like peer code review, peer expertise can be applied to improve plan accuracy and task coverage.
- Checklist-based review of plans. Checklist-based code reviews are powerful ways to reduce defects in shipped code. Likewise, specific mistakes in plans and estimates are frequently repeated, and reviewing plans with checklists yields greater accuracy.
- History. Consulting history and applying historic on-task time to future estimates is notoriously effective at producing accurate plans and estimates. It should be pointed out that if we refactor plans as we go, we will always have a perfect historical record of our actual historical delivery times3 for leverage when making future plans and refactoring future tasks and estimates.
- Scope reduction. This is one of the most underappreciated and powerful tools when reconciling plans with upstream commitments. Software development efforts frequently have enormous room for scope reduction, but attempting scope reduction without a plan and estimates is like trying to find your keys in the dark.
This is a limited list. As an industry if we pursue this path, we can evolve both industry and context-specific, personalized expertise. Some are already there and capitalizing on it.
Footnotes
1 This plays out on Twitter, among other places, as an evergoing #yesestimates and #noestimates hashtag battle.
2 Incidentally estimates are often wrong for the exact-same reasons that our code can be wrong.
3 The estimate for a task becomes precise and accurate at least at the moment we complete the task. So if we are regularly refactoring, every task will finally achieve its accurate estimate: the time it actually took to complete the task. Of course, this is a degenerate case to make a point.